
24 Nov 2017
This blog post kicks off a series of ‘war stories’ that I’ll be sharing, where I’ll be covering my thought-process on tackling interesting issues - in a bid to help others, and hopefully garner feedback on alternative solutions or methods to arrive at a better solution, faster.
Tutorials are great, but they cover the case when things go well - and there’s just as much to be learnt in times when things don’t sail as smoothly. As a full-stack software engineer, there’s no end to the learning and the frequent hurdles that come with only being able to study so deeply into each area of the stack. Let’s begin!
The problem
For one of our applications, we were getting monitoring reports that the website is down. Sure enough, upon visiting the website, it had slowed to an absolute crawl, if loading at all.
In almost every case, this is down to slow running queries or processes that are holding up resources. It’s a costly database query that is unindexed, a background progress that is I/O heavy etc - and yet, there was no such evidence. CPU stable, plenty of free memory, disks hardly working. Nothing in NewRelic, Monit or Munin pointed to the cause of the hold-up. The only metric of concern was that throughput would drop considerably.
And the quick fix? To restart the Apache web server, which brought services back online instantly.
Only for the issue to recur shortly after…
Being hosted on AWS, there has been multiple occasions where network issues have impacted requests, such as a fault directly at AWS or higher upstream. Such an issue would result in requests not even reaching the server and cause a resulting drop in server resources. In this case, all was remaining pretty consistent on the server end, with regards to resources and HTTP traffic.
So an Apache restart would temporarily resolve matters, and NewRelic (which is specifically tracking requests only to the Ruby on Rails application) was showing no increase of activity or cause for concern. Our Passenger server (which sits between Apache and the Rails application) was showing no abnormal activity, further narrowing things down. This pointed to the issue specifically being requests that are reaching Apache but going no further.
Apache helpfully has the mod_status module, which provides a bunch of helpful statistics via the apachectl status command. You are likely to already have this module loaded - which can be confirmed by running sudo httpd -M on Apache 2.x, where you should see the status_module (shared) entry. The status check revealed the following, that we were not exceeding our MaxClients limits, and that many requests were in a ..reading.. state:
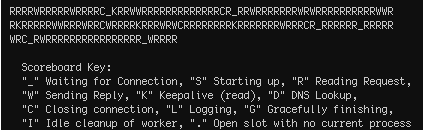
With ExtendedStatus enabled in your httpd.conf, you also have access to extra stats which can be obtained by running sudo apachectl fullstatus. Among a few genuine requests to various parts of the web application, the majority were requests that look as follows:

Requests with no recognised Client or targeted VHost, and of particular note - the length of the running request: upwards of 200 seconds in the examples above. My initial hunch was that we’re seeing a resource limit on such requests and that these will need clamping down through sysctl config changes as described well on a ServerFault thread on ‘apache requests stuck in reading’ state found here. The config changes weren’t the answer, but it immediately lead to the culprit and resulting solution…
The solution
The many requests stuck in a reading state was caused by a type of denial of service attack called ‘Slowloris’. The name is pretty fitting, derived from a cute sounding but apparently pretty vicious little animal. But look at those eyes!

As Wikipedia explains well, the attack is carried out by attempting to keep open many connections to your webserver - and keep them open for as long as possible, effectively choking out other traffic and bringing things to a crawl. It’ll commence a request, occasionally drip-feed subsequent HTTP headers, but never complete. Of the popular web servers, only Apache 1.x and 2.x is affected.
There are a range of solutions - with the most accessible being to configure Apache to mitigate the impact by putting restrictions on how long such requests can hang around for, and then insisting on an maximum time between parts of the request. This can be achieved with another Apache module which is likely to be available and present in your http modules folder (which you’ll find at a location like /etc/httpd/modules), and will need to be loaded in.
The loading of the mod_reqtimeout module, and configuring is accomplished by adding the following something like the following to your httpd.conf file:
LoadModule reqtimeout_module modules/mod_reqtimeout.so
RequestReadTimeout header=20-40,MinRate=500 body=20-40,MinRate=500
The above configuration states that Apache should allow for the request header/body to take at least 20 seconds, and to increase this timeout for every 500 bytes received. It’s a conservative configuration, which can and probably should be tightened further - although the timeout would need to account for the SSL handshake time and thus, if applicable, should not be set too low.
Upon restarting the webserver - the number of Slowloris looking requests was significantly reduced, and none were hanging around more than the 20 seconds we’ve configured. Likewise, the apachectl status reveals a much healthier looking set of requests, in varying stages of completion, and set of workers ready to take up incoming requests.
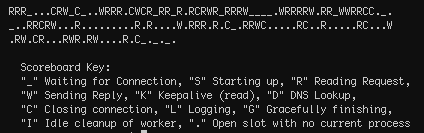
So this puts out the fire, but only serves to mitigate the issue, not resolve it completely. There happens to be a range of other Apache modules which can limit the damage of a Slowloris attack, but it’s the mod_reqtimeout discussed here that is module officially recommended by Apache. A ‘complete’ solution to this variation of a HTTP slow request attack would be to either change to a webserver that does not fall victim to such an attack, such as nginx.
And there we have it. The Slowloris attack tamed.
And it’s easy to forgive. I mean, you did see those eyes?!